Got feedback? Additional questions? Just want to have a friendly chat?
Get in touch!
Introduction
The distribution analytics page shows distributions: on one axis the intervals are plotted while the other shows how many times a value in this interval occurs in the data.
This count is calculated by looping over the records in your data set that match the configured filter, assigning them to an interval and counting how many records ended up in each interval.
There are multiple ways to do this conversion from records to a single count per interval, but at this moment the platform only supports a single way: record-based calculations.
Record based calculations
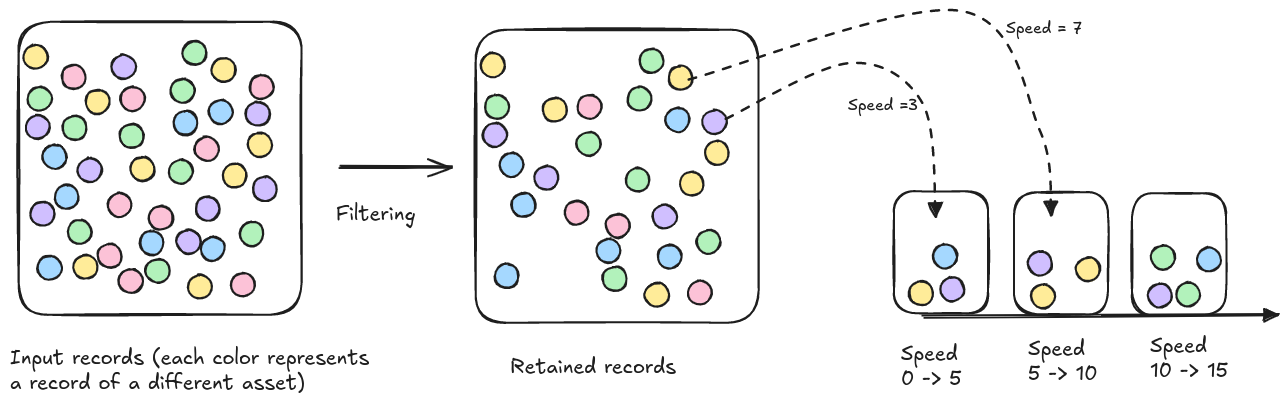
The distribution calculations in the xyzt.ai platform currently happen on a record-based level.
When requesting the distribution for a certain property (e.g. speed), the value of that speed property is extracted from each of the records that are retained after filtering.
Based on that property value, we assign the record to an interval. At the end, the number of records assigned to each interval is counted.
Figure 1. Individual records are assigned to intervals based on the value of the property
Got feedback? Additional questions? Just want to have a friendly chat?
Get in touch!