Got feedback? Additional questions? Just want to have a friendly chat?
Get in touch!
|
This article only applies to movement data
This article is only relevant when working with movement data, not when working with time series data. You can read more about the differences between the two in this article. |
Data versus metadata
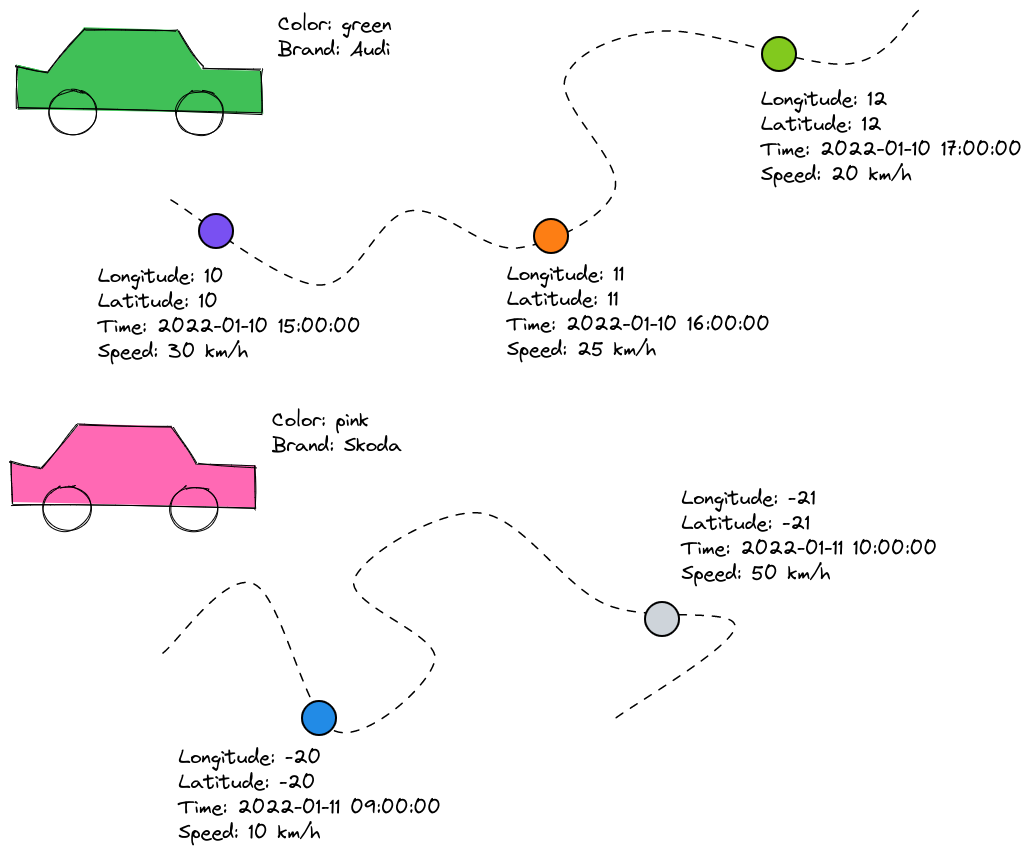
Assume you have car location data with the following properties:
-
The location of the car
-
The timestamp at which the location was recorded
-
The speed of the car at that same moment
-
The color of the car
-
The brand of the car
Figure 1. Recording the location and speed along the trajectory of a car
There are 2 different ways to store this information:
-
All information stored in a single file
Car id Timestamp Longitude Latitude Speed Color Brand 2
2022-01-10 09:00:00
-20
-20
10
Pink
Skoda
2
2022-01-10 10:00:00
-21
-21
50
Pink
Skoda
1
2022-01-10 15:00:00
10
10
30
Green
Audi
1
2022-01-10 16:00:00
11
11
25
Green
Audi
1
2022-01-10 17:00:00
12
12
20
Green
Audi
Note how the
colorandbrandproperty always contain the same value for a specific car. -
Divide the information over two files.
-
One file with all information that changes each time a new location is recorded
Car id Timestamp Longitude Latitude Speed 2
2022-01-10 09:00:00
-20
-20
10
2
2022-01-10 10:00:00
-21
-21
50
1
2022-01-10 15:00:00
10
10
30
1
2022-01-10 16:00:00
11
11
25
1
2022-01-10 17:00:00
12
12
20
-
One
.csvfile with all the information that remains fixed over timeCar id Color Brand 1
Green
Audi
2
Pink
Skoda
This file contains what we call metadata
-
Benefits of using metadata files
There are some benefits of dividing the information over data and metadata files (if you have control over how your files are produced):
-
Less data to upload: typically you end up with smaller file sizes when you can extract the metadata into a separate file instead of having to repeat it over and over again.
-
Ability to update the metadata: the platform allows to delete the metadata and replace it with new metadata, even when the data has already been processed. This only requires to re-process the metadata and not all the location records.
Got feedback? Additional questions? Just want to have a friendly chat?
Get in touch!