Got feedback? Additional questions? Just want to have a friendly chat?
Get in touch!
The platform supports 5 types of data sets:
-
Movement data: Data from tracking moving assets where both the location and properties can vary over time.
-
Points data: Data from independent, unrelated measurements, each with its own location.
-
Geometry data: Data defined for fixed locations with properties that do not change over time.
-
Time series data: Data with time varying properties measured or computed for fixed locations.
-
Movement path data: Data from tracking assets that move along a (road) network.
All types of data sets can be created by uploading files to the platform. Geometry and time series data can also be created directly by connecting to a PostgreSQL database.
Type 1: Movement data
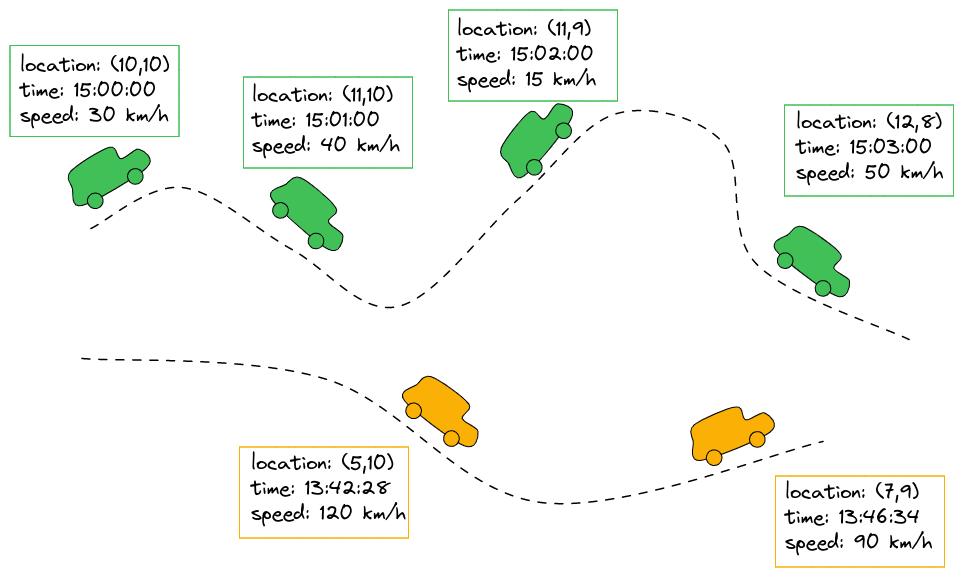
Data of this type is obtained by tracking a moving asset over time. The asset could be anything: cars, boats, airplanes, people, … .
Figure 1. Tracking and recording the locations and speeds of moving cars
For each asset, at certain time intervals, the location and additional properties are recorded and stored.
Examples of movement data
Examples of this are:
-
AIS data, which contains the position and properties of vessels over time
-
Similar datasets exist for airplanes, cars
-
Tracking the location of people by tracking their mobile phones
Files the platform expects for movement data
Data sets of this type use the following files:
-
CSV or Parquet data files where each line contains:
-
The unique id of the asset
-
The location (longitude, latitude) of the asset
-
The timestamp at which the location was recorded
-
The values of any additional properties at the specified time (for example the speed or the heading)
-
-
Optionally, CSV or Parquet metadata files for information that doesn’t change over time. Each line contains:
-
The unique id of the asset
-
The properties that don’t vary over time (for example color, brand)
-
See the data versus metadata article for more information on the differences between the two.
Type 2: Points data
Data of this type is obtained by collecting individual, independent measurements, each at its own location.
Each point at least has a location, and optional other properties.
Examples of points data
Examples of this are:
-
Events data, with each record representing an independent event occurring at a given location and time. E.g.: vehicle accident events data, harsh breaking data, …
-
Static point location data. E.g.: the location of all houses in a municipality, each with its number of residents.
Files the platform expects for points data
Data sets of this type use the following files:
-
CSV or Parquet data files where each line contains:
-
The location (longitude, latitude) of the point where the measurement applies to or where the event takes place
-
(Optional) The timestamp at which the measurement/event was recorded
-
(Optional) The values of any additional properties.
-
Note: if an identifier and timestamp are present, and records share the same identifier, you should probably consider using movement (if the locations for the same identifier differ) or time series (if the location remains constant for each identifier) data instead.
Metadata is not supported for points data: as the records in point data are unrelated, there is no use case for metadata for this type of data.
Type 3: Geometry data
File-based geometry data
Data of this type are GeoJSON or SHP files, containing:
-
Locations (areas, lines or points)
-
Properties for each of those locations
The benefit of creating data sets for these files instead of creating a background or area of interest layer for it are that you can use the properties in the data to style and filter the features.
Files the platform expects for geometry data
Data sets of this type use the following files:
-
GeoJSON or SHP files which define features consisting of geometries and properties. Each feature in each file represents a single shape, and defines:
-
A geometry (point, line, polygon)
This geometry is used during visualization of the data on the spatial map of the visual analytics page.
-
A unique identifier for the location
-
Additional (static) properties about the location.
This can include a property defining a human-readable display name or any other custom property such as Speed limit.
When working with (road) networks, following special properties are recommended to provide:
-
Priority Level: A priority level property that gives higher importance to certain features. This property should have a value of
1for highest priority (e.g., highways) and9for lowest priority (e.g., tertiary roads). -
Reverse ID: For bi-directional networks (e.g., with two-way roads), a property that denotes the identifier of the opposing direction. For instance, some data sets use identifiers of the form
23484113_0for the road segments, where-23484113_0is used for the opposing road direction. By specifying this property, the platform understands which roads are two-way.
-
-
Note that Geometry data has to be created first before being able to work with Movement path data.
Following file formats are supported for geometry files:
-
GeoJSON files can be uploaded as
.geojsonor as gzipped.geojson.gzwith a single file in each gzip file -
SHP files need to be uploaded as
.zipfiles as they by themselves consist of multiple files
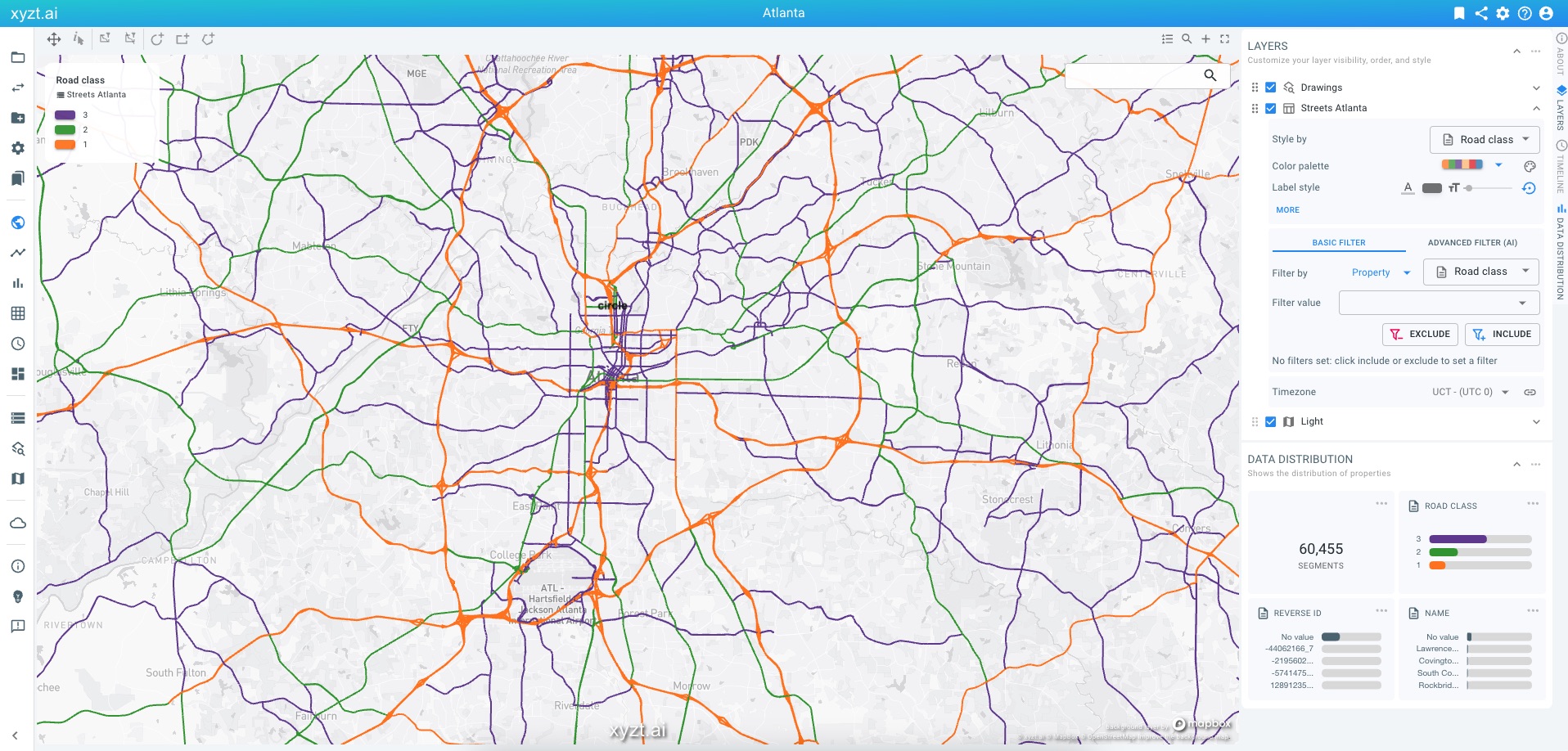
Figure 2. Geometry data set with road features, where
Road class is used as a special priority level property to allow for multi-scale data handling.Database-defined geometry data
Geometry data sets can also be created by directly connecting to a PostgreSQL database. The geometries and associated properties should be defined in a single table with the PostGIS extension enabled. The primary key column defines the identifier.
When creating a geometry data set from a table, the platform automatically creates default data property definitions. Use the wizard to modify if needed.
Also for these data sets, the special properties can be indicated, such as display name, priority level, reverse id.
Note that no data is copied to and processed by the platform. All queries are performed on-the-fly on the PostgreSQL database. Performance hence depends largely on the database instance.
Type 4: Time series data
File-based time series data
Data of this type is obtained by measuring (or computing and aggregating) values in a fixed location or over a fixed area.
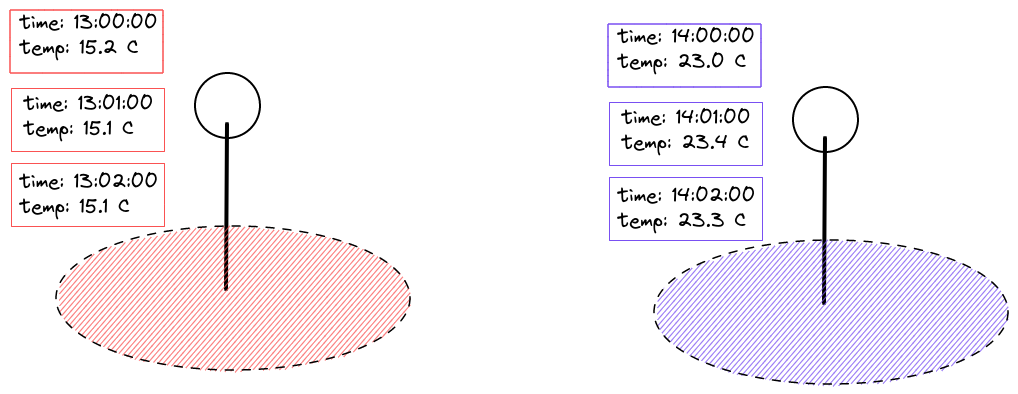
Figure 3. Measuring the temperature at regular time intervals in a fixed location
Those measurements can be taken at a certain point location, or represent a measurement over a certain area such as a road or city neighborhood.
Examples of time series data
Examples of this are:
-
Average temperature measurement (for a computer, a room, a country, …).
-
A traffic counter keeping track of how many vehicles are on a road segment.
-
Aggregate floating vehicle data where for different road segments the number of vehicles, average speed, speed percentiles,… are measured over time.
-
A person counter measuring how many people are in a room at all times.
Files the platform expects for time series data
Data sets of this type use the following files:
-
GeoJSON or (zipped) SHP files which define the features with their geometry and constant properties. Each feature in each geometry file represents a single entity (e.g., a sensor location, a street segment, a neighborhood in a city,…), and defines:
-
A geometry (as part of the feature), representing the coverage area of the measurement.
This geometry is used during visualization of the data on the spatial map of the visual analytics page.
-
A unique identifier for the entity (sensor, street, area,…).
-
Additional properties about the entity (for example the brand or type of the device, or the name of the street or area for use as display name).
When working with data defined on road networks, you can give more importance to larger roads using a priority level property and you can work with two-way roads using a reverse ID property:
-
Priority Level: A priority level property that gives higher importance to certain features. This property should have a value of
1for highest priority (e.g., highways) and9for lowest priority (e.g., tertiary roads). -
Reverse ID: For bi-directional networks (e.g., with two-way roads), a property that denotes the identifier of the opposing direction. For instance, some data sets use identifiers of the form
23484113_0for the road segments, where-23484113_0is used for the opposing road direction. By specifying this property, the platform understands which roads are two-way.
-
-
-
CSV or Parquet data files where each line contains:
-
The unique measurement device or area identifier to indicate to which device or area the recordings of that specific row belong.
-
The timestamp of when the recording took place.
-
Values for each measurement that was taken (for example the temperature).
-
Database-defined time series data sets
Similar to database-defined geometry data sets, the platform supports creation of time series data sets that directly connect to PostgreSQL.
For time series the data needs to be defined in two separate tables:
-
A geometry table, similar to the geometry data set using the PostGIS extension for the geometry column.
-
A time series table, with a column and foreign key referencing the primary key of the geometry table. The time series table contains the records with time stamps and attributes.
During creation of a time series data set, the platform automatically suggests the data and metadata properties configuration. These can be adapted through the wizard or the API.
Type 5: Movement path data
Data of this type is obtained by tracking a moving asset over time along a (road) network. The asset could be anything: cars, trains, but also, boats, airplanes, people, … .
For each asset, at certain time intervals, the location on the road network and additional properties are recorded and stored.
Examples of movement path data
Examples of this are:
-
INRIX trip paths data, where the road network is divided in road segments and trips are defined as a vehicle following a sequence of these road segments.
-
Similar datasets exist for train networks.
Files the platform expects for movement path data
A movement path data set depends on a geometry data set that defines the road network.
First, define a geometry data set using:
-
(gzipped) GeoJSON or zipped SHP files, where each feature, contains:
-
A unique identifier
-
And following optional, but highly recommended properties:
-
Priority Level: A priority level property that gives higher importance to certain features. This property should have a value of
1for highest priority (e.g., highways) and9for lowest priority (e.g., tertiary roads). -
Reverse ID: For bi-directional networks (e.g., with two-way roads), a property that denotes the identifier of the opposing direction. For instance, some data sets use identifiers of the form
23484113_0for the road segments, where-23484113_0is used for the opposing road direction. By specifying this property, the platform understands which roads are two-way. -
Display Name: A property that defines the display name. For instance a feature with identifier
23484113_0can have a propertydisplayNamewith valueMemorial Drive Southwest.
-
-
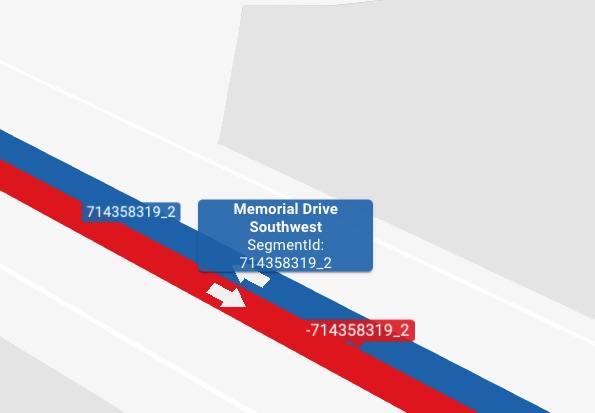
Figure 4. Movement path data is defined on a (road) network with potential bi-directional roads.
The movement path data set is defined by pointing it to the GeoJSON data set with the (road) network and by providing following files:
-
CSV or Parquet data files where each line contains:
-
The unique id of the asset
-
The feature identifier of the (road) segment in the GeoJSON file
-
The timestamp at which the vehicle is at the relevant road segment
-
The values of any additional properties at the specified time (for example the speed or the heading)
-
-
Optionally, CSV or Parquet metadata files for information that doesn’t change over time. Each line contains:
-
The unique id of the asset
-
The properties that don’t vary over time (for example color, brand)
-
See the data versus metadata article for more information on the differences between the two.
Got feedback? Additional questions? Just want to have a friendly chat?
Get in touch!