Got feedback? Additional questions? Just want to have a friendly chat?
Get in touch!
Available parts
- Goal
- About INRIX trip paths data (current)
- Uploading INRIX trips data
- Getting started using INRIX trips data
About INRIX Trip Paths data
In INRIX Trip Paths data, a trip is a sequence of road segments a vehicle traverses when driving from point A to point B.
-
Each trip consists of a sequence of road segment traversals. The trip itself has associated properties such as the type of vehicle, the trip length.
-
Each road segment traversal corresponds to the vehicle, passing (a part of) the road segment during a certain time interval. It has associated properties such as the entry and exit time, the entry and exit offset, and the vehicle speed.
-
Each road segment corresponds to a specific part of a street. It typically starts at an intersection of roads and runs up to the next intersection.
Each trip is defined by a unique identifier (the TripId). Each road segment is also defined by a unique identifier (the SegmentId).
The road segment traversals link the two: each traversal refers both to a TripId and a SegmentId (i.e., TripId and SegmentId are properties of a road traversal), indicating that the vehicle of the linked trip traversed the linked segment at a particular time. An INRIX Trip Paths data set may consist of millions of trips and billions of road traversals.
Below we explain what the data looks like.
Directory structure
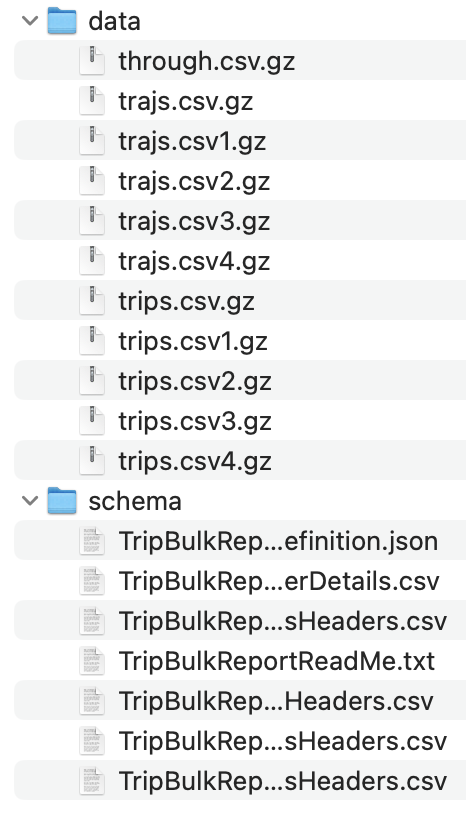
INRIX Trip Paths data can be delivered in many ways, including as a downloadable zip file, or an S3 bucket. Once you downloaded and/or unzipped one of the trip report folders, it should look similar to this:
Figure 1. The directory structure of an INRIX Trip Paths data set.
Don’t worry if the directory structure is different. The most important are the trajs.csv*.gz and trips.csv*.gz files in the data folder. These are the files that you will have to upload to the xyzt.ai platform.
The extension .gz denotes that the files have been compressed with gzip.
Sometimes the files are delivered not compressed, i.e., they have the extension .csv instead of .csv.gz. The xyzt.ai platform accepts both formats.
|
The road network files are delivered separately as SHP files.
SHP files
The SHP files define the road network, they contain the spatial geometry of all individual road segments the trajectory files may refer to.
They are typically delivered as a compressed ZIP file, containing one or more .shp files and associated .dbf and .shx files. Each .shp file defines the geometric coordinates of a set of road segments, the associated .dbf file contain the attributes for each road segment, such as the segment id, the road name, the road class and (in case of two-way street data) the id of the reverse road segment.
The SHP files only contain static, road-specific information, they don’t contain any temporal or trip-specific properties. As such, they remain constant over time and can be shared amongst multiple Trip Paths data sets.
The xyzt.ai platform can directly handle the compressed .zip format, and will automatically unpack and parse all SHP files contained in the uploaded zip files.
Trips files
The trips files are contained in the trips folder. This contains all constant information about each trip. For example, the type of vehicle that completed the trip. If your data set contains 1 million different trips, then the .csv files in this folder will have a combined 1 million rows, 1 row for each trip.
Note that in the example above, there is only one trips.csv.gz file, but in case you have a large data set, there can be multiple, such as trips.csv.gz, trips.csv1.gz, etc.
Each trip defines a number of properties as defined in the schema folder’s TripBulkReportTripsHeaders.csv file:
TripId,DeviceId,ProviderId,Mode,StartDate,StartWDay,EndDate,EndWDay,StartLocLat,StartLocLon,EndLocLat,EndLocLon,GeospatialType,ProviderType,ProviderDrivingProfile,VehicleWeightClass,ProbeSourceType,OriginZoneName,DestinationZoneName,EndpointType,TripMeanSpeedKph,TripMaxSpeedKph,TripDistanceMeters,MovementType,OriginCbg,DestCbg,StartTimezone,EndTimezone,WaypointFreqSec,StartQk,EndQk
For performing analysis in the xyzt.ai platform, the most important properties are the TripId, VehicleWeightClass, and TripDistanceMeters. Geospatial and temporal properties are less important, as the platform will derive them automatically from the trajectories.
Trajectories files
The trajs folder contains the temporal data. It consists of CSV files, where each line in the CSV files contains a trip id, a road segment id, and a start and end timestamp, representing a vehicle entering and leaving a particular road segment at a certain point in time. In addition, it contains a number of additional attributes related to the event, such as the speed the vehicle was driving when it passed that road segment. This is the larger folder as every trip typically has tens to hundreds of segment traversals.
The data is partitioned in separate files, each approximately 256 MB, and they are named as trajs.csv.gz, trajs.csv1.gz, etc. Each file contains multiple segment traversals of different trips.
Again, in the schema folder there is a file called TripBulkReportTrajectoriesHeaders.csv that describes the different columns in the waypoints CSV files:
TripId,DeviceId,ProviderId,TripTimezone,TrajIdx,TrajRawDistanceM,TrajRawDurationMillis,SegmentId,SegmentIdx,LengthM,CrossingStartOffsetM,CrossingEndOffsetM,CrossingStartDateUtc,CrossingEndDateUtc,CrossingSpeedKph,OnRoadNetworkSnapCount,ErrorCodes
As you can see, the TripId is also present in these files, as well as the SegmentId and the CrossingSpeedKph. These are the most important properties used for analyzing traffic flows from floating vehicle data.
Please refer to your INRIX contact for full information on all data properties.
In the next part, you will learn how to ingest this data in the xyzt.ai platform.
Next part
Go to the next part: Uploading INRIX trips data
Got feedback? Additional questions? Just want to have a friendly chat?
Get in touch!